5 The FAIR Data Principles
So what makes our data ‘Open’ and how do we facilitate it being open to all? This can be summarised by what is called the FAIR Data principles.
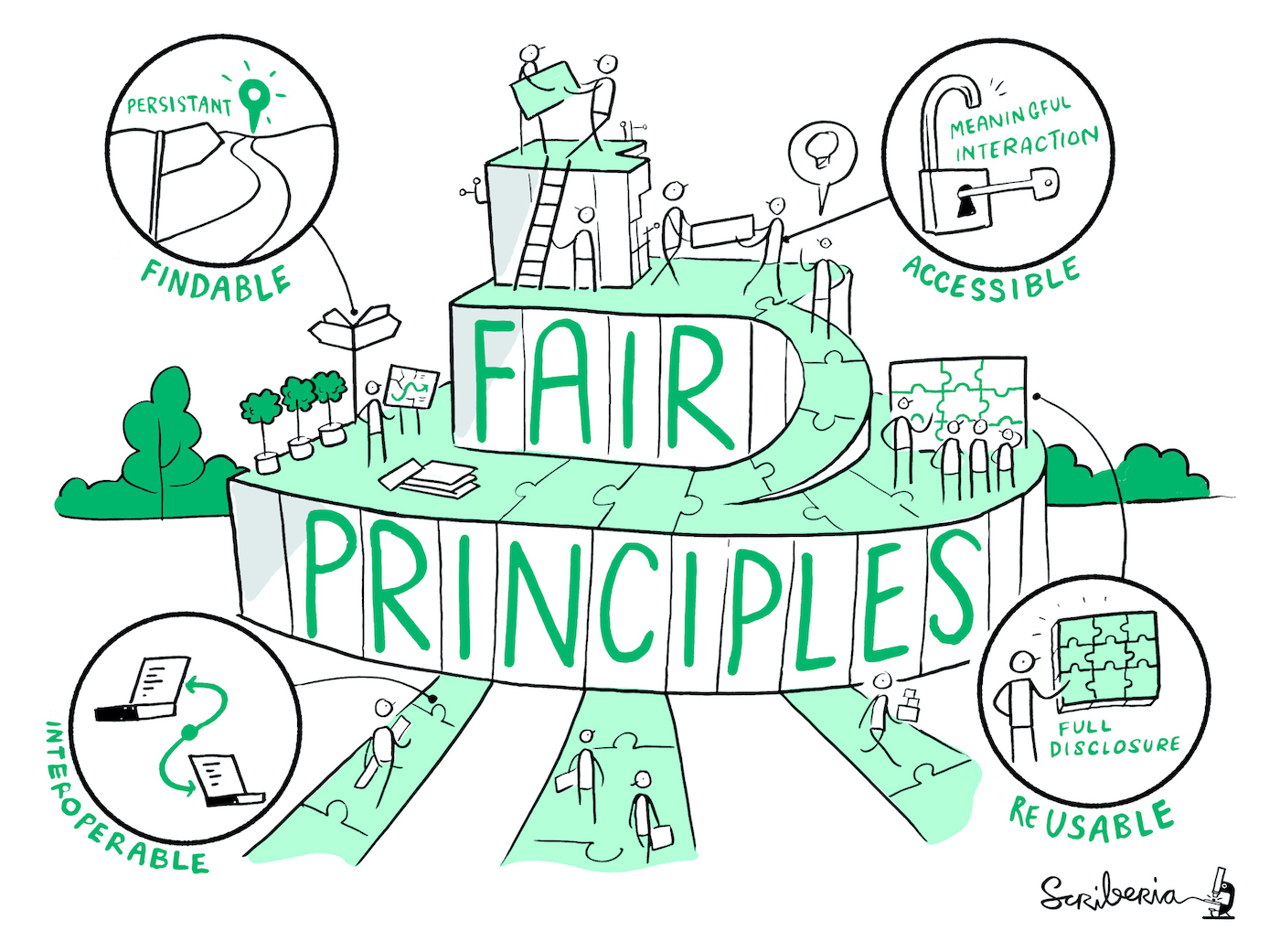
The FAIR data principles is a series of four interlinked principles that work together to ensure that knowledge we discover throughout our research is integrated and reused by the wider community (either researchers or the general public) beyond the lifetime of a discrete project.
FAIR stands for:
- Findable
- Accessible
- Interoperable
- Reusable
The FAIR Data Principles provide a concise and measurable set of principles that can be put into practice within our research. These four aspects each provide a method to break down how we should go about making our data open as possible.
The paper below links to the original discussion of the FAIR Data Principles for data management. Although it relates more specifically to scientific data, it provides a useful source of information for understanding the background to this concept.
Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018. DOI: https://doi.org/10.1038/sdata.2016.18
5.1 FAIR Data in theory….
How does FAIR data work in theory? Consider the questions below when it comes to your own research data.
- Findable - Are you (and others) able to find your data?
- Accessible- Once a user has found it, how do they access it? Is it open source?
- Interoperable - Is your data integrated with other sources (within a larger catalogue) and can it be used with other workflows?
- Reusable - Is your data well described so that it can be used, combined, and extended in different settings?
5.2 FAIR Data in practice….
And how does FAIR data work in Practice? Think about the methods below and how you could apply them to your research data.
- Findable: Use persistent identifiers, such as a DOI for objects or an ORCID for people. Add appropriate metadata to your data and make your data available via searchable resources (e.g. the Ariande Portal).
- Accessible: Make your data freely available as an open access resource and make your data preserved for the long term in a digital repository (more on this below).
- Interoperable: Use standardised vocabularies when describing your data, such as FISH (Forum on Information Standards in Heritage) or the Getty AAT (Art & Architecture Thesaurus).
- Reusable: Ensure that your data is issued with a data licence and includes necessary descriptive and contextual information for reuse (perhaps consider writing a data paper).
The paper below by Emma Karoune and Esther Plomp, both contributors to the Turing Way, is a detailed explanation on how you can share your archaeological data and make it more reproducible. The paper contains some practical solutions and a glossary of terms, which makes it a really valuable resource.
Karoune, E., and Plomp, E. (2022) Removing Barriers to Reproducible Research in Archaeology. Zenodo, ver. 5 peer-reviewed and recommended by Peer Community in Archaeology. DOI: https://doi.org/10.5281/zenodo.7320029
5.3 Digital Repositories
Ensuring your data is FAIR may feel a bit overwhelming, depending on the size of your project and the types of data you may be working with. The good news is that Digital Repositories are available to assist you and provide services to ensure your data is Findable, Accessible, Interoperable and Reusable.
The purpose of a Digital Repository (sometimes also referred to as a data archive) is:
- To collect, store and preserve digital data.
- Ensure that each archive is accompanied by rich metadata (data that provides information on your data).
- Catalogue archives using persistent identifiers, such as DOIs.
- Create standardised practices for the collection and preservation of different data types.
When considering which archive may be the best for your data it is important to note that there are a number of different repositories for different types of data. Repositories can vary based on discipline, geographic location or data type.
Here are a number of different repositories that may be useful for archaeological research data:
- ADS - The Archaeology Data Service is the leading accredited digital repository for archaeology and heritage data generated by UK-based fieldwork and research. Founded in 1996 the ADS provides discipline specific expertise to a wide range of data types used in archaeology.
- tDAR - The Digital Archaeological Record is based in the US but is an international digital repository for the digital records of archaeological investigations.
- Figshare - Figshare is an online open access repository where researchers can preserve and share their research outputs, including figures, datasets, images, and videos. In some instances Universities have adopted a version of Figshare for their own institutional repository.
- Zenodo - An Open source repository originally commissioned by the European Commission providing a catch-all open repository for EC funded research. Built and developed by researchers, “to ensure that everyone can join in Open Science”. The repository is a free to use and growing repository for researchers and is very useful in uploaded presentations and documentation from your research project.
- Institutional repositories - Many universities now host their own institutional data repository (an example from the University of York). If you are a researcher in a University you have likely been encouraged to upload your publication preprints in your University repository for the purposes of REF. These types of repositories are usually free to use (depending on the quantity of data you want to archive), however, they will usually not be able to provide discipline specific requirements.
If you are interested in how the ADS makes our data FAIR, please read this page on FAIR Data on the ADS website.